
⌛ زمان مطالعه: حدود 15 دقیقه
🔍 علم داده چیست؟
علم داده یک حوزه میان رشتهای است که تکنیکهایی از آمار، علوم کامپیوتر و دانش تخصصی حوزه کاربردی را برای استخراج بینشهای معنادار از مجموعه دادههای بزرگ و پیچیده ادغام میکند. فرآیند علم داده شامل جمعآوری، پاکسازی، تحلیل و تفسیر دادهها است. دانشمندان داده از ابزارها و تکنیکهای متنوعی مانند تحلیل آماری، یادگیری ماشین و مصورسازی داده برای کشف الگوها، روندها و روابط درون دادهها استفاده میکنند.
❓ چرا علم داده امروز اهمیت دارد؟
سازمانها امروزه با حجم دادهای چندین برابر بیش از یک دهه پیش روبرو هستند. محاسبات ابری مقرون به صرفه شده و ابزارهای مدرن یادگیری ماشین، تبدیل داشبوردهای ساده به مدلهای مستقرشده را عملی کردهاند که مستقیماً بر درآمد، هزینه و ریسک تأثیر میگذارند. سه مزیت اصلی علم داده عبارتند از:
-
📊 تصمیمگیری آگاهانه:
در دنیایی که بیشاطلاعاتی (Information Overload) یک چالش دائمی است، علم داده به تصمیمگیرندگان ابزارهایی میدهد تا از میان سروصدا عبور کرده و بینشهای عملی استخراج کنند.
-
🔮 قدرت پیشبینی (Predictive Power):
مدلسازی پیشبین علم داده به سازمانها امکان میدهد روندها، رفتار مشتریان و تغییرات بازار را پیشبینی کنند و استراتژیهای پیشگیرانه تدوین نمایند.
-
💡 پیشبرد نوآوری:
علم داده با آشکارسازی الگوها و همبستگیهای پنهان در دادهها، موتور نوآوری محسوب میشود و شناسایی نیازهای برآورده نشده و توسعه محصولات جدید را تسهیل میکند.
♻️ چرخه حیات علم داده (Data Science Lifecycle)

توضیح دقیق مراحل:
-
🎣 شکار داده (Capture): جمعآوری دادههای خام از منابع مختلف مانند سنسورها، پایگاهدادهها و APIها.
-
🗄️ نگهداری داده (Maintain): پاکسازی، ذخیرهسازی و سازماندهی دادههای خام برای استفادههای بعدی.
-
⚙️ پردازش داده (Process): دانشمندان داده به دنبال الگوها و روندهای مختلف در دادههای آمادهشده میگردند تا میزان مفید بودن آنها برای پیشبینی را ارزیابی کنند.
-
📈 تحلیل داده (Analyse): کاوش عمیق در دادهها برای انجام پیشبینیها و یافتن بینشهای مناسب با استفاده از تکنیکهای تحلیلی مختلف.
-
📢 ارتباط نتایج (Communicate): ارائه یافتهها به فرمتهای قابل فهم مانند نمودارها، داشبوردها و گزارشها به ذینفعان.
🗂️ انواع مسائل در علم داده
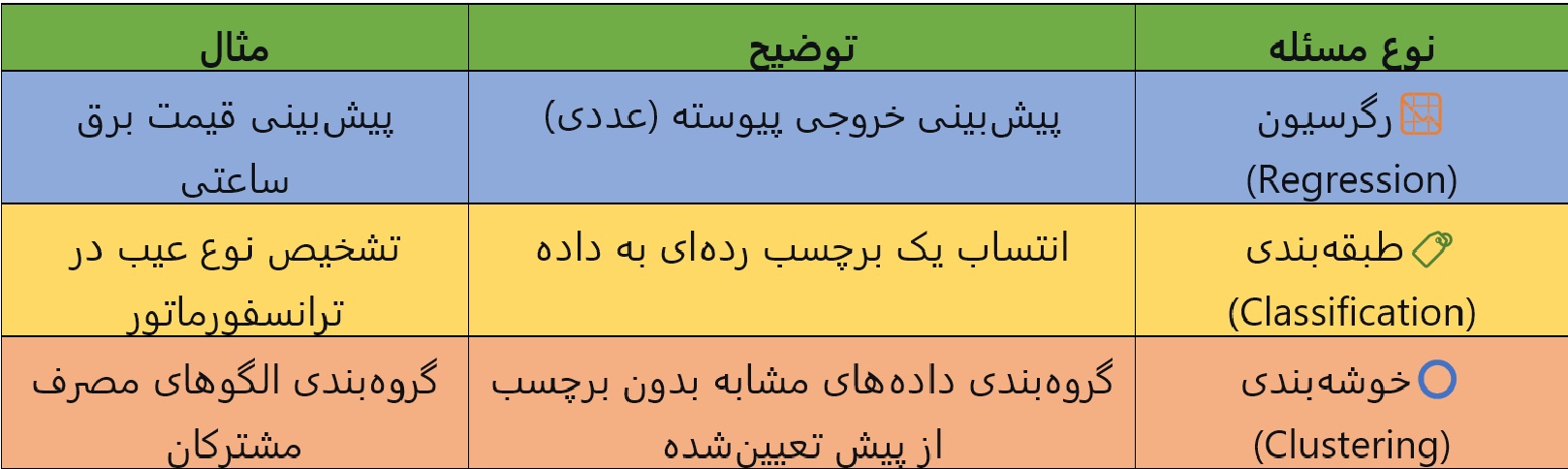
⚡ کاربردها در مهندسی برق
1️⃣ پیشبینی پایداری شبکه هوشمند (Smart Grid Stability Prediction)
یکی از چالشهای اصلی سیستمهای قدرت مدرن، حفظ پایداری شبکه در حضور منابع انرژی تجدیدپذیر متغیر و بارهای نوسانی است. پژوهشهای جدید نشان دادهاند که مدلهای یادگیری عمیق مانند شبکههای GRU (Gated Recurrent Unit) میتوانند با دقت ۹۷ درصد پایداری شبکههای هوشمند را پیشبینی کنند.
یک مطالعه با استفاده از مجموعه دادهای شامل ۶۰,۰۰۰ نمونه از ثابتهای زمانی، سطوح توان و متریکهای مرتبط، عملکرد مدلهای مختلفی از جمله RNN، LSTM، GRU و ترنسفورمرها را مقایسه کرده است. نتایج نشان داد که مدل GRU با تنظیم فراپارامترهای بهینه، دقت اعتبارسنجی ۹۷.۰۳ درصد را به دست میآورد که بالاترین میزان در بین مدلهای مورد بررسی است.
2️⃣ تشخیص ناهنجاری در دادههای سری زمانی شبکه قدرت با شبکههای انحراف گراف
تشخیص ناهنجاری در دادههای تخمین حالت شبکه قدرت برای پایداری و قابلیت اطمینان شبکه بسیار حیاتی است. روشهای سنتی مبتنی بر قوانین و مهندسی ویژگی دستی، در محیط پویا و دادهمحور شبکههای قدرت مدرن با چالش مواجه هستند.
شبکههای انحراف گراف (Graph Deviation Networks – GDN) راهحلی نوآورانه ارائه میدهند. مطالعات نشان میدهد که رویکرد نیمهنظارتی GDN میتواند با نمره F1 بالای ۹۸ درصد برای سیستمهای IEEE 6-bus، 14-bus و 30-bus عمل کند و زمان همگرایی تخمین حالت را بیش از نصف کاهش دهد.
3️⃣ مدیریت انرژی هوشمند با دوقلوهای دیجیتال و یادگیری تقویتی عمیق
با افزایش نفوذ منابع انرژی تجدیدپذیر (RES) و خودروهای برقی (EVs)، مدیریت انرژی در سطح مصرفکنندگان-تولیدکنندگان (Prosumers) به یک چالش پیچیده تبدیل شده است. پژوهشگران چارچوبی ارائه دادهاند که دوقلوهای دیجیتال (Digital Twins) مبتنی بر یادگیری عمیق را با یادگیری تقویتی (RL) و تحلیل دادههای بزرگ ترکیب میکند. نتایج نشان میدهد این رویکرد با نفوذ بیش از ۶۰ درصد انرژی تجدیدپذیر، شاخص پایداری شبکه را بالای ۰.۹۰۵ نگه میدارد.
4️⃣ پایش سلامت ترانسفورماتورها با چارچوب کلان داده مبتنی بر هوش مصنوعی
یک چارچوب مقیاسپذیر مبتنی بر کلان داده، با ادغام فناوریهایی مانند Apache Kafka برای جریانسازی بیدرنگ داده، Apache Spark برای پردازش در مقیاس بزرگ، و مدلهای یادگیری ماشین (LSTM، ARIMA، XGBoost) برای تحلیل پیشگویانه، شاخص سلامت ترانسفورماتور (THI) را به صورت پویا محاسبه میکند.
🎛️ کاربردها در مهندسی کنترل
1️⃣ کنترل پیشبین مدل دادهمحور (Data-Driven MPC)
کنترل پیشبین مدل (MPC) یکی از پیشرفتهترین روشهای کنترلی است، اما پیادهسازی آن معمولاً به مدل دقیق سیستم و منابع محاسباتی قابل توجه نیاز دارد. رویکردهای دادهمحور، جایگزین امیدوارکنندهای ارائه میدهند که کنترلکننده را مستقیماً از دادههای ورودی-خروجی اندازهگیری شده طراحی میکند.
یک طرح MPC خود-محرک دادهمحور برای سیستمهای خطی ناشناخته، تنها به دادههای اولیه ورودی-خروجی متکی است و نویزهای فرآیند و اندازهگیری را در نظر میگیرد. این روش فشار محاسباتی کنترلکننده را کاهش داده و همزمان استحکام و پایداری سیستم را تضمین میکند.
2️⃣ طراحی کنترل فیدبک خروجی استاتیک از داده
طراحی کنترل فیدبک خروجی استاتیک (SOF) با استفاده از دادههای ورودی-حالت-خروجی جمعآوری شده از سیستم حلقهباز، امکان کنترل سیستمهای چندورودی-چندخروجی (MIMO) را بدون داشتن مدل دقیق فراهم میکند. آزمایشها روی سیستمهای MIMO و سیستم آیرودینامیکی دو-روتوره نشان داده است که کنترلکننده SOF دادهمحور، پایداری این سیستمها را تضمین میکند.
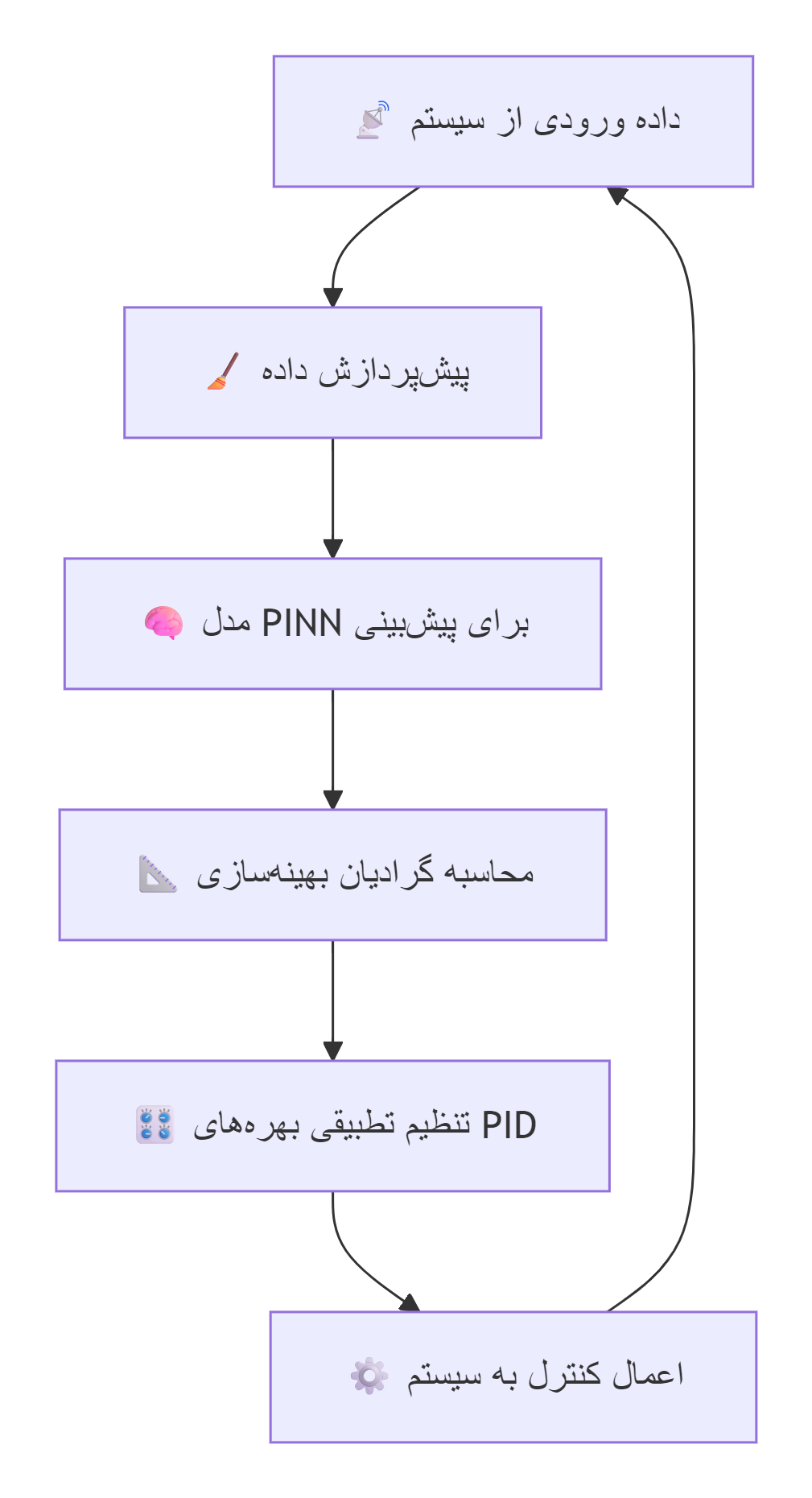
3️⃣ کنترل PID تطبیقی دادهمحور با شبکههای عصبی آگاه از فیزیک
روش جدیدی با استفاده از شبکههای عصبی آگاه از فیزیک (PINNs) برای طراحی کنترلکننده PID تطبیقی ارائه شده است. در این روش، گرادیانهای بهینهسازی بهره PID از طریق تمایز خودکار شبکههای PINN به دست میآید.
4️⃣ کنترلهای توزیعشده دادهمحور
راهکار جدید مبتنی بر همکاری ابر-لبه (Cloud-Edge Collaborative) که از تحلیل دادههای بزرگ استفاده میکند، قادر است به طور تطبیقی شناسایی مدل و بهروزرسانی قانون کنترل را انجام دهد و به شرایط عملیاتی متعدد سازگار شود.
🏭 کاربردها در صنعت
🛠️ نگهداری و تعمیرات پیشگویانه (Predictive Maintenance)
نگهداری پیشگویانه (PdM) یکی از بزرگترین زمینههای کاربرد علم داده در صنعت است. این رویکرد از هوش مصنوعی و تحلیل داده برای پیشبینی خرابی تجهیزات در تولید هوشمند استفاده میکند. ارزیابیهای تجربی نشان میدهد این رویکردها میتوانند عملکرد عملیاتی را تا حدود ۲۰ درصد افزایش و مصرف منابع را تا ۱۵ درصد کاهش دهند.
📦 بهینهسازی تولید و زنجیره تامین
علم داده با پیشبینی دقیق تقاضا، بهینهسازی موجودی و خودکارسازی فرآیندها، به کاهش هزینهها و افزایش کارایی کمک میکند. الگوریتمهای پیشرفته تحلیل داده میتوانند الگوهای پیچیده مصرف مواد اولیه، زمانهای توقف ماشینآلات و نرخ تولید را شناسایی و برنامهریزی تولید را بهینه کنند.
🌍 کاربردها در دنیای واقعی
🚗 صنعت خودرو: اتومبیلهای خودران
خودروهای خودران ساعتی حدود ۱ ترابایت داده از سنسورهای لیدار، رادار، دوربینها و GPS تولید میکنند. الگوریتمهای علم داده این دادهها را در زمان واقعی پردازش کرده تا اشیاء اطراف را شناسایی، مسیر حرکت را برنامهریزی و تصمیمات لحظهای رانندگی را اتخاذ کنند.
💳 بانکداری و امور مالی: کشف تقلب
سیستمهای کشف تقلب بانکی، الگوهای تراکنش مشتریان را در زمان واقعی تحلیل میکنند. یک مدل یادگیری ماشین که روی میلیونها تراکنش واقعی و تقلبی آموزش دیده، میتواند تراکنشهای مشکوک را با دقت بالایی شناسایی و قبل از وقوع خسارت، آنها را مسدود کند.
🏢 صنعت بیمه: ارزیابی ریسک
شرکتهای بیمه از مدلهای پیشبینی کننده مبتنی بر هزاران متغیر (سن، سابقه رانندگی، موقعیت جغرافیایی، نوع خودرو و …) برای محاسبه حق بیمه مشتریان استفاده میکنند. این مدلها با تحلیل الگوهای تاریخی خسارت، ریسک هر مشتری را کمی کرده و قیمتگذاری عادلانهتری ارائه میدهند.
🏥 مراقبتهای بهداشتی
در بیمارستانها، الگوریتمهای یادگیری ماشین سوابق الکترونیک سلامت بیماران (شامل علائم حیاتی، نتایج آزمایشگاهی، تشخیصهای قبلی و …) را تحلیل کرده و بیماران در معرض خطر بالای ابتلا به سپسیس یا نارسایی عضو را پیش از بروز علائم بالینی جدی شناسایی میکنند.
💡 جمعبندی
علم داده به عنوان یکی از کلیدیترین حوزههای فناوری اطلاعات و هوش مصنوعی، از یک ابزار تحلیلی ساده به یک ضرورت استراتژیک در تمامی صنایع تبدیل شده است. از پیشبینی پایداری شبکههای هوشمند با دقت ۹۷ درصد و تشخیص ناهنجاری در سیستمهای قدرت تا طراحی کنترلکنندههای تطبیقی دادهمحور و نگهداری پیشگویانه تجهیزات صنعتی، علم داده ثابت کرده است که میتواند بهرهوری، قابلیت اطمینان و نوآوری را به طور همزمان ارتقا دهد.
آینده علم داده با پیشرفت فناوریهایی مانند محاسبات لبه (Edge Computing) و اینترنت اشیاء (IoT) به سمت تحلیلهای بلادرنگ و تصمیمگیری خودکار پیش میرود.
📚 مراجع معتبر علمی (۲۰۲۵–۲۰۲۶)
-
Knowledge Academy. (2025). What is Data Science? A Comprehensive Guide.
-
Educative.io. (2026). Introduction to Data Science: Tools and Techniques for Analysis.
-
IEEE Conference. (2025). Deep Learning Models for Predicting Stability in Smart Grids. DOI: 10.1109/ICECA62545.2025.11115731
-
ScienceDirect. (2025). Anomaly detection in smart grid time-series data using Graph Deviation Networks. Engineering Applications of Artificial Intelligence, Vol. 142.
-
Wiley Online Library. (2025). Deep Learning-Enabled Digital Twins for Prosumers: A Holistic Energy Management Framework for Smart Grids. International Transactions on Electrical Energy Systems.
-
IEEE Xplore. (2025). Data-Driven Self-Triggered MPC and Stability Analysis. IEEE Transactions on Automatic Control, Vol. 71, pp. 23083-23094.
-
Elsevier. (2025). Static output-feedback control design from data. European Journal of Control, Vol. 85, 101260.
-
arXiv. (2025). Data-Driven Adaptive PID Control Based on Physics-Informed Neural Networks. arXiv:2510.04591.
-
Springer. (2025). A Literature Review on Enhancing Predictive Maintenance in Smart Manufacturing Industries. Operations Research Forum.
- IEEE Xplore. (2025). Enhancing Smart Manufacturing with Secure Predictive Maintenance: a Data-Driven Approach.
📖 واژهنامه تخصصی (انگلیسی–فارسی)
| English Term | فارسی |
|---|---|
| 📊 Data Science | علم داده |
| 💻 Data-Driven | دادهمحور |
| 🔧 Predictive Maintenance | نگهداری پیشگویانه |
| ⚡ Smart Grid | شبکه هوشمند |
| 🪞 Digital Twin | دوقلوی دیجیتال |
| ⚠️ Anomaly Detection | تشخیص ناهنجاری |
| 🤖 Machine Learning | یادگیری ماشین |
| 🧠 Deep Learning | یادگیری عمیق |
| 🎛️ Model Predictive Control (MPC) | کنترل پیشبین مدل |
| 📚 Supervised Learning | یادگیری بانظارت |
| 🔍 Unsupervised Learning | یادگیری بدون نظارت |
| 🔘 Clustering | خوشهبندی |
| 🏷️ Classification | طبقهبندی |
| 📈 Regression | رگرسیون |
| ⏱️ Time-Series Data | داده سری زمانی |
| 🧩 Feature Extraction | استخراج ویژگی |
| ⚡ Real-Time Analytics | تحلیل بلادرنگ |
![]()